Use Cuda code in Unreal Engine 5
CUDA stands for Compute Unified Device Architecture, a parallel computing platform and an API (Application Programming Interface) model developed by Nvidia. Using Cuda programming language we can implement applications involving heavy computations in GPU, making use of it's parallelism.
Using cuda code in Unreal Engine 5 enable us to shift computational heavy steps into GPU, this is extremely useful if you are creating image/voxel analysis and visualization applications in UE5.
Integration of Cuda invloves two phases, building Cuda code into a static library then linking them in UE5 project.
Building Cuda scripts into a Static Library
- Install Cuda toolkit in Windows from here.
- Create a new project in Visual Studio with Cuda Runtime 11.7 (let say the name is
test_cudaue). - Change the mode from Debug to Release.
- In the Solution Explorer at the right side, right click on the your project name and click on properties. In the properties change Configuration Type from application to static library.
- Now remove the automatically generated
kernel.cu, instead create two new files namedtest_cudaue.cuandtest_cudaue.h. It has a basic function for testing the addition of two arrays in the GPU.
test_cudaue.h
{`#pragma once
#include <string>
#include "cuda_runtime.h"
#include "vector_types.h"
#include "vector_functions.h"
#include "device_launch_parameters.h"
cudaError_t testCudaAddition(int* c, const int* a, const int* b, unsigned int size, std::string* error_message);
`}
test_cudaue.cu
{`#include "test_cudaue.h"
__global__ void addKernel(int* c, const int* a, const int* b)
{
int i = threadIdx.x;
c[i] = a[i] + b[i];
}
__global__ void addKernel2(int4* c, const int4* a, const int4* b)
{
int i = threadIdx.x;
c[i].x = a[i].x + b[i].x;
c[i].y = a[i].y + b[i].y;
c[i].z = a[i].z + b[i].z;
c[i].w = a[i].w + b[i].w;
}
// Helper function for using CUDA to add vectors in parallel.
cudaError_t testCudaAddition(int* c, const int* a, const int* b, unsigned int size, std::string* error_message)
{
int* dev_a = 0;
int* dev_b = 0;
int* dev_c = 0;
cudaError_t cuda_status;
// Choose which GPU to run on, change this on a multi-GPU system.
cuda_status = cudaSetDevice(0);
if (cuda_status != cudaSuccess) {
*error_message = "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?";
goto Error;
}
// Allocate GPU buffers for three vectors (two input, one output) .
cuda_status = cudaMalloc((void**)&dev_c, size * sizeof(int));
if (cuda_status != cudaSuccess) {
*error_message = "cudaMalloc failed!";
goto Error;
}
cuda_status = cudaMalloc((void**)&dev_a, size * sizeof(int));
if (cuda_status != cudaSuccess) {
*error_message = "cudaMalloc failed!";
goto Error;
}
cuda_status = cudaMalloc((void**)&dev_b, size * sizeof(int));
if (cuda_status != cudaSuccess) {
*error_message = "cudaMalloc failed!";
goto Error;
}
// Copy input vectors from host memory to GPU buffers.
cuda_status = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
if (cuda_status != cudaSuccess) {
*error_message = "cudaMemcpy failed!";
goto Error;
}
cuda_status = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice);
if (cuda_status != cudaSuccess) {
*error_message = "cudaMemcpy failed!";
goto Error;
}
// Launch a kernel on the GPU with one thread for each element.
addKernel << <1, size >> > (dev_c, dev_a, dev_b);
// Check for any errors launching the kernel
cuda_status = cudaGetLastError();
if (cuda_status != cudaSuccess) {
*error_message = "addKernel launch failed: " + std::string(cudaGetErrorString(cuda_status));
goto Error;
}
// cudaDeviceSynchronize waits for the kernel to finish, and returns
// any errors encountered during the launch.
cuda_status = cudaDeviceSynchronize();
if (cuda_status != cudaSuccess) {
*error_message = "cudaDeviceSynchronize returned error code " + std::to_string(cuda_status) + " after launching addKernel!";
goto Error;
}
// Copy output vector from GPU buffer to host memory.
cuda_status = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost);
if (cuda_status != cudaSuccess) {
*error_message = "cudaMemcpy failed!";
goto Error;
}
Error:
cudaFree(dev_c);
cudaFree(dev_a);
cudaFree(dev_b);
return cuda_status;
}
`}
- Right click on the project name in the solution explorer and click on Build. This should make a
test_cudaue.libin thetest_cudaue/x64/Releasefolder.
Linking with UE5 Project
- Create
[UE5ProjectRoot]/ThirdParty/Cuda/include&[UE5ProjectRoot]/ThirdParty/Cuda/lib. - Copy the header file (test_cudaue.h) from the cuda project in to this include folder.
- Copy the static lib file (test_cudaue.lib) from the cuda project in to the lib folder.
- Edit the
[UE5ProjectRoot]/Source/[ProjectName]/[ProjectName].build.cs
using UnrealBuildTool; using System.IO; public class [projectname] : ModuleRules { private string poject_root_path { get { return Path.Combine(ModuleDirectory, "../.."); } } public bool LoadCuda(ReadOnlyTargetRules Target) { string custom_cuda_lib_include = "ThirdParty/Cuda/include"; string custom_cuda_lib_lib = "ThirdParty/Cuda/lib"; PublicIncludePaths.Add(Path.Combine(poject_root_path, custom_cuda_lib_include)); PublicAdditionalLibraries.Add(Path.Combine(poject_root_path, custom_cuda_lib_lib, "test_cudaue.lib")); string cuda_path = "C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v11.7"; string cuda_include = "include"; string cuda_lib = "lib/x64"; PublicIncludePaths.Add(Path.Combine(cuda_path, cuda_include)); PublicAdditionalLibraries.Add(Path.Combine(cuda_path, cuda_lib, "cudart_static.lib")); // PublicAdditionalLibraries.Add(Path.Combine(cuda_path, cuda_lib, "nppif.lib")); // PublicAdditionalLibraries.Add(Path.Combine(cuda_path, cuda_lib, "nppicc.lib")); // PublicAdditionalLibraries.Add(Path.Combine(cuda_path, cuda_lib, "nppig.lib")); return true; } public [projectname](ReadOnlyTargetRules Target) : base(Target) { PCHUsage = PCHUsageMode.UseExplicitOrSharedPCHs; bEnforceIWYU = true; PublicDependencyModuleNames.AddRange(new string[] { "Core", "CoreUObject", "Engine", "InputCore" }); PrivateDependencyModuleNames.AddRange( new string[] {}); LoadCuda(Target); } }
- Change the projectname with yours.
- After compiling create a new C++ Actor class named
TestCudaActorand editTestCudaActor.hinto the following with a Blueprint callable function:
#pragma once #include "CoreMinimal.h" #include "GameFramework/Actor.h" #include "test_cudaue.h" #include "cuda_runtime.h" #include "TestCudaActor.generated.h" UCLASS() class PROJECTNAME_API ATestCudaActor : public AActor { GENERATED_BODY() public: // Sets default values for this actor's properties ATestCudaActor(); UFUNCTION(BlueprintCallable, Category = "projectname") bool CUDATest() { const int size = 2; const int arr1[size] = { 5, 4}; const int arr2[size] = { 2, 8}; int output[size] = { 0 }; std::string error_message; // run cuda code cudaError_t cuda_status = testCudaAddition(output, arr1, arr2, size, &error_message); if (cuda_status != cudaSuccess) { UE_LOG(LogTemp, Warning, TEXT("Cuda addition failed!\n")); UE_LOG(LogTemp, Warning, TEXT("%s"), *FString(error_message.c_str())); return false; } UE_LOG(LogTemp, Warning, TEXT("{5, 4} + {2, 8} = {%d,%d}"), output[0], output[1]); return true; } protected: // Called when the game starts or when spawned virtual void BeginPlay() override; public: // Called every frame virtual void Tick(float DeltaTime) override; };
- Here also replace the projectname with yours.
- Right click on the
TestCudaActorc++ class and create a Blueprint. Then edit its event graph:
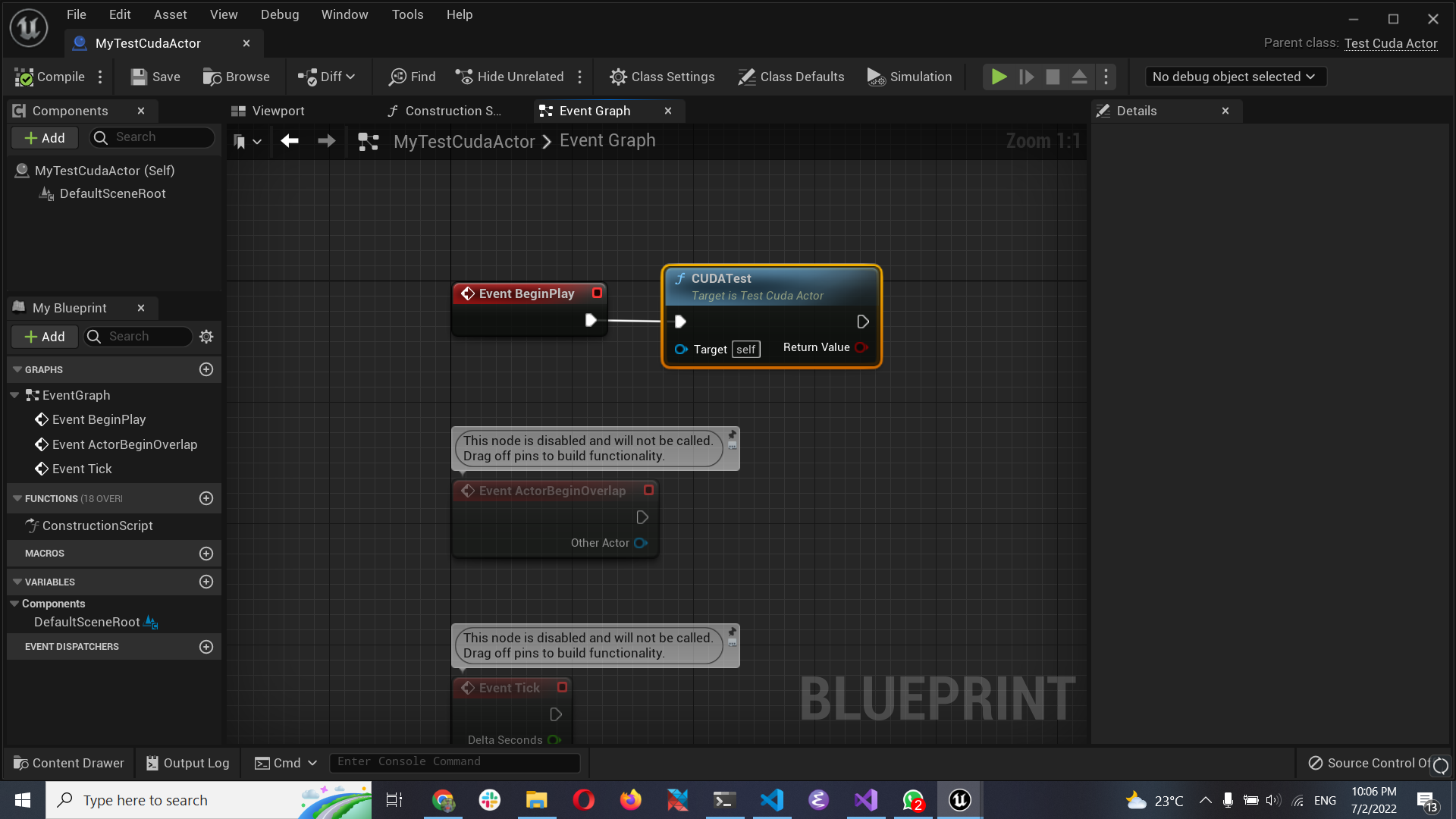
- Place the blueprint in the level and run the game. You will see the following output log as the confirmation of the integration.
